Znajdź najkrótszą ścieżkę i do domu
Magiczna komenda jaką daje nam silnik i pozamiatane. Nie no co wy, zwróci nam najkrótszą drogę ale po ilości relacji.
MATCH (s:Point),(e:Point),
p = shortestpath((s)-[*]-(e))
WHERE s.name = 'JASŁO' AND e.name = 'RZESZÓW'
return p
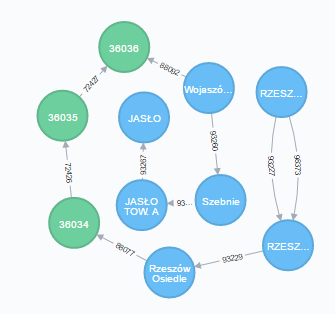
No ale nam chodzi o odległość, a posiadamy strukturę punktów osadzonych na kawałkach drogi, a poruszamy się między punktami, droga to tylko medium. Więc w głowie pojawia się pomysł bezpośredniego połączenia punktów.
MATCH (s:Point)-[r:Stay]-(t:Segment)
where r.lineNo = t.lineNo
with distinct s,r.km as km, t.lineNo as lineNo
order by km
with collect({s:s,km:km,lineNo:lineNo}) as one , collect({s:s,km:km,lineNo:lineNo}) as two
UNWIND one as ss
with ss , filter(next IN two WHERE ss.lineNo = next.lineNo and next.km >= ss.km and NOT next.s.name = ss.s.name)[0] as nss
with ss.s as fi, nss.km-ss.km as distance , ss.lineNo as lineNo, nss.s as se
where se is not null
merge (fi)-[:Connect{distance: distance ,lineNo: lineNo}]-(se)
Przy tym skrypcie się już trochę rozpoznałem Cypher'a, ale jeśli ktoś ma inny pomysł na połączenie tego to proszę bardzo :).
Mając na połączone punkty no to tylko sumować odległości dzieki reduce i dawaj najkrótszą.
START startNode=node:node_auto_index(name="Start"),
endNode=node:node_auto_index(name="Finish")
MATCH p=(startNode)-[:NAVIGATE_TO*]->(endNode)
RETURN p AS shortestPath,
reduce(distance=0, r in relationships(p) : distance+r.distance) AS totalDistance
ORDER BY totalDistance ASC
LIMIT 1;
I lepiej tego nie puszczać jeśli się ma więcej niż 100 nodów. XD Gdy rozpoczeła się walka z brakiem RAM i mając już 5 min zastanawiania się dlaczego to tak długo, zrozumiałem że gość tak naprawdę robi iloczyn kartezjański i wszystko próbuje obliczyć... Porażka, Jak takie zajefajne grafy i na 25k Pointów i 60k odcinów się wysypuje.
No ale 90% problemu to brak zrozumienia jak to działa. I oczywiście każdy miał na studiach algorytmy i było o takim na D, co tak szybko szuka.
Daleko szukać i głowić się nie trzeba, jest już zaimplementowany jako plugin do neo,  neo4j-apoc-procedures.
neo4j-apoc-procedures.
MATCH (s:Point{name:'JASŁO'}),(e:Point{name:'RZESZÓW'})
CALL apoc.algo.dijkstra(s, e, 'Connect', 'distance') YIELD path, weight
RETURN path, weight
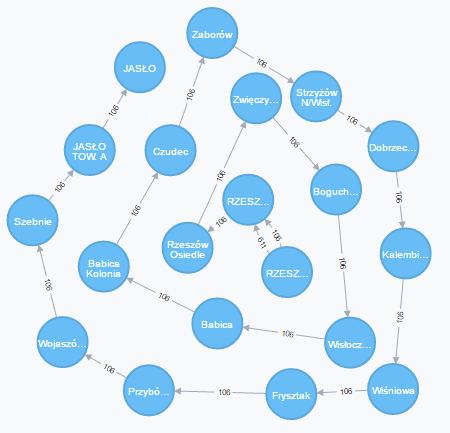
No i to już jest faktyczna prawdziwa najkrótsza ścieżka.
Teraz temat co jeśli nie możemy jechać przez np Czudec. Na szybko mam tylko taki pomysł żeby skopiować relacje które są dostępne czyli bez Czudca, a następnie wyszukać połączenie, i oczywiście pamiętać żeby to chwilowe powiązanie usunąć.
MATCH (s:Point)-[c:Connect]-(t:Point)
where s.name <> 'Czudec' and t.name <> 'Czudec'
merge (s)-[:Connect_tempWOCzud{distance: c.distance ,lineNo: c.lineNo}]-(t)
Jak sprawdziłem skopiowanie 2k relacji bez 2 bo akurat tyle miał Czudec to 450ms, więc jeszcze nie tak źle. Gorsza jest trasa bez przejazdu przez Czudec gdzie okazuje się że muszę nadgonić 100km aby go ominąć. Taką mamy mapę :)
MATCH (s:Point{name:'JASŁO'}),(e:Point{name:'RZESZÓW'})
CALL apoc.algo.dijkstra(s, e, 'Connect_tempWOCzud', 'distance') YIELD path, weight
RETURN path, weight
.png)
Próbując wytyczyć alternatywne ścieżki okazało się że dane są nie dokładne a najlepszy błąd to stworzenie punktu Granica Państwa gdzie z odległością 0 można się teleportować z Zgorzelca do Cieszyna :)
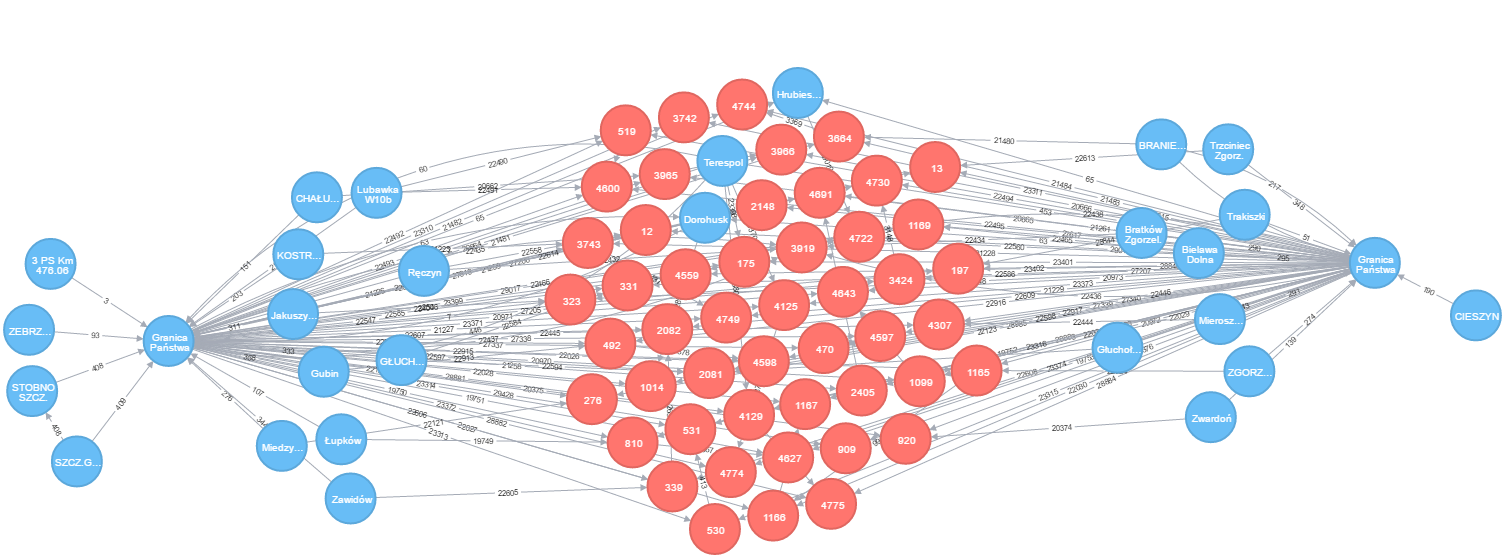
Tyle eksperymentów z czystym Neo, następny krok to kawałek, który będzie miał za zadanie obsługę obsługę całej transakcji bez wyłączonych odcinków itd.
I DO DOMU :D
